
Sinds Screaming Frog’s SEO Spider v20 uitkwam, heeft het de mogelijkheid om custom JavaScript snippets te gebruiken voor acties of data extractie.
Deze versie komt al met wat ingebouwde snippets, maar hier is er nog één die je kan gebruiken. Specifiek, een extractie snippet die gebruik maakt van TextRazor om entiteiten in bulk te herkennen via een tool die je waarschijnlijk al gebruikt.Waarom? (Als je dat moet vragen, lees de ‘Definitive Guide on Entity SEO’. Voor degene die het niet vragen, laten we beginnen.
TextRazor’s API Key
Om te beginnen hebben we als eerste een API key van TextRazor nodig. Die is gratis, tot 500 requests per dag.Het verkrijgen van de key is simpel: gewoon naar de signup pagina gaan en je account aanmaken. Hierna zie je je API key.
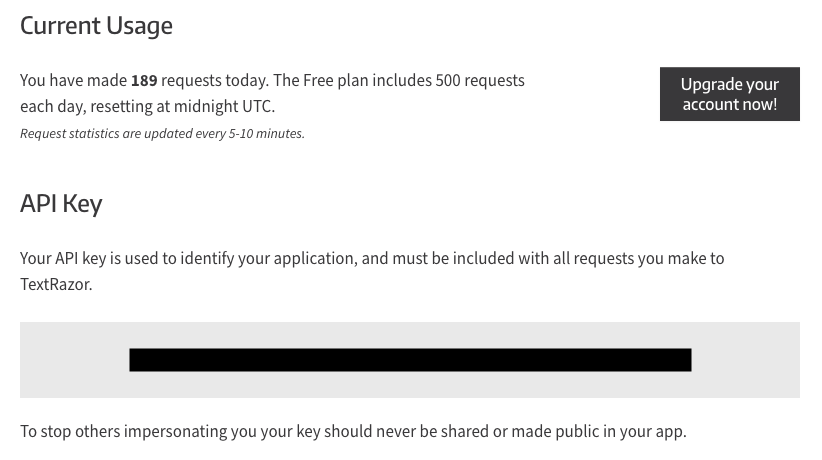
Als je dit hebt gedaan, is het tijd voor het leukere werk.
Screaming Frog instellen
Custom JavaScript snippets is een nieuwe feature vanaf v20. Deze is al eventjes uit dus ga ik er vanuit dat je die al hebt. Is dat niet zo, moet je toch gaan updaten.
De snippet toevoegen
// TextRazor Entity Extraction
//
// IMPORTANT:
// You will need to supply your API key below which will be stored
// as part of your SEO Spider configuration in plain text.
// You can set 'languageOverride' if you want, but overall TextRazor
// is doing OK in identifying the language.
// API key and language override variables (keep your API key static in Screaming Frog)
const TEXTRAZOR_API_KEY = '';
const languageOverride = ''; // Leave blank if you don't want to override. Check https://www.textrazor.com/languages for supported languages
const userContent = document.body.innerText; // This captures the text content of the page
let requestCounter = 0; // Initialize request counter
const maxRequestsPerDay = 500; // Set the maximum requests per day, the free plan has a 500 requests per day
// The free plan has a limit of 2 concurrent requests, the delay will handle this
function delay(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function extractEntitiesWithDelay() {
const entities = [];
const chunkSize = 5000;
const textChunks = [];
for (let i = 0; i < userContent.length; i += chunkSize) {
textChunks.push(userContent.substring(i, i + chunkSize));
}
for (let i = 0; i < textChunks.length; i++) {
if (requestCounter >= maxRequestsPerDay) {
console.log('Reached the maximum number of requests for the day.');
break;
}
const text = textChunks[i];
console.log('Sending text chunk to TextRazor:', text.slice(0, 200));
const bodyParams = new URLSearchParams({
text: text,
extractors: 'entities,topics',
});
// Conditionally add the language override if it's provided
if (languageOverride) {
bodyParams.append('languageOverride', languageOverride);
}
const response = await fetch('https://api.textrazor.com/', {
method: 'POST',
headers: {
'x-textrazor-key': TEXTRAZOR_API_KEY,
'Content-Type': 'application/x-www-form-urlencoded'
},
body: bodyParams.toString()
});
if (response.ok) {
const data = await response.json();
console.log('TextRazor response:', data); // Log the response for debugging
if (data.response.entities) {
entities.push(...data.response.entities);
requestCounter++;
}
} else {
const errorText = await response.text();
console.error('TextRazor API error:', errorText);
}
if (i < textChunks.length - 1) {
await delay(1000);
}
}
return entities;
}
// First version had a lot of invalid entities, this filters a bunch of them
function isValidEntity(entity) {
const invalidTypes = ["Number", "Cookie", "Email", "Date"];
const entityId = entity.entityId || entity.matchedText;
if (entity.type && Array.isArray(entity.type) && entity.type.length > 0) {
if (invalidTypes.includes(entity.type[0]) || /^[0-9]+$/.test(entityId)) {
return false;
}
} else if (/^[0-9]+$/.test(entityId)) {
return false;
}
return true;
}
function processEntities(entities) {
const entitiesDict = {};
entities.forEach(entity => {
if (isValidEntity(entity)) {
const entityId = entity.entityId || entity.matchedText;
const entityName = entity.matchedText.toLowerCase(); // Convert entity name to lowercase
const freebaseLink = entity.freebaseId ? `https://www.google.com/search?kgmid=${entity.freebaseId}` : '';
const wikiLink = entity.wikiLink || ''; // Ensure we're capturing the Wikipedia link correctly
if (entityId !== 'None' && isNaN(entityName)) { // Filter out numeric-only entities
const key = entityName + freebaseLink; // Unique key based on name and link
if (!entitiesDict[key]) {
entitiesDict[key] = {
entity: entityName,
count: 1,
freebaseLink: freebaseLink,
wikiLink: wikiLink
};
} else {
entitiesDict[key].count += 1;
}
}
}
});
const result = Object.values(entitiesDict).filter(item => item.entity && item.entity !== 'None'); // Filter out empty or 'None' entities
return JSON.stringify(result);
}
return extractEntitiesWithDelay()
.then(entities => {
if (entities.length === 0) {
console.warn('No entities found in the response.');
}
return seoSpider.data(processEntities(entities));
})
.catch(error => seoSpider.error(error));Om de snippet toe te voegen ga je in Screaming Frog naar het configuratiescherm:
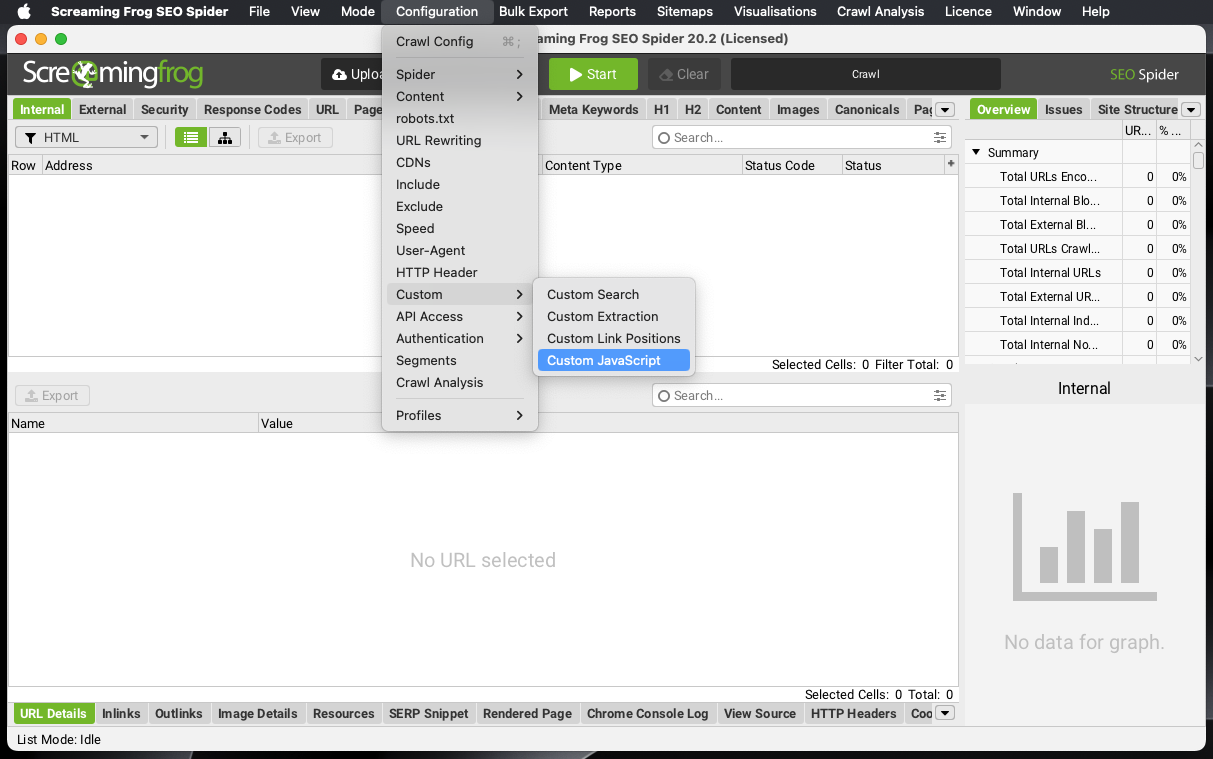
Hiermee open je een nieuw scherm waar je een aantal opties hebt. Je moet klikken op ‘Add from Library’ of gewoon op ‘Add’. De library is interessant omdat hier ook de meegeleverde snippets staan. En de users library, waarin je eigen snippets komen.
Eventueel kan je ook nog snippets importeren of exporteren via JSON bestanden.
Voor nu klik je gewoon op ‘Add’. Hiermee open je een nieuw venster met een editor waarin je de snippet moet plakken. Vergeet niet je eigen API key toe te voegen aan de snippet.
Heb je dit gedaan, dan kan je gelijk naast de editor een URL ingeven om je snippet te testen.
Testen maar
Oke, om de snippet te laten werken heb je dus een API key nodig. Maar een belangrijke stap is om naar je crawl configuratie te gaan en rendering op JavaScript te zetten.
De gratis versie van TextRazor heeft een limiet van 500 requests per dag. Dus de snippet ook. En omdat de API slechts twee requests tegelijk pakt, heb ik een delay in de snippet gebouwd. Crawlen zal dus niet heel snel zijn. Maar omdat je JavaScript rendering aan hebt is dat sowieso al langzaam. En aan te raden om gewoon een lijst met URLs te gebruiken.
Als je gaat crawlen krijg je een extra kolom met data met JSON output. Dit bevat:
- Entity naam
- Aantal keer dat de entity voorkomt
- Freebase link (als bekend)
- Wikipedia link (als bekend)
Volgende stappen
Zijn aan jou. Je kan exporteren naar Google Sheets / csv, etc.